stage4day3section5-7
Section5:Seq2Seq
・2つのネットワークをドッキングしたもの
・文の意味を抽出して、文の意味を基に別の表現を得る
・encoder - Decorderモデルの一種
・機械対話や機械翻訳に使用されている
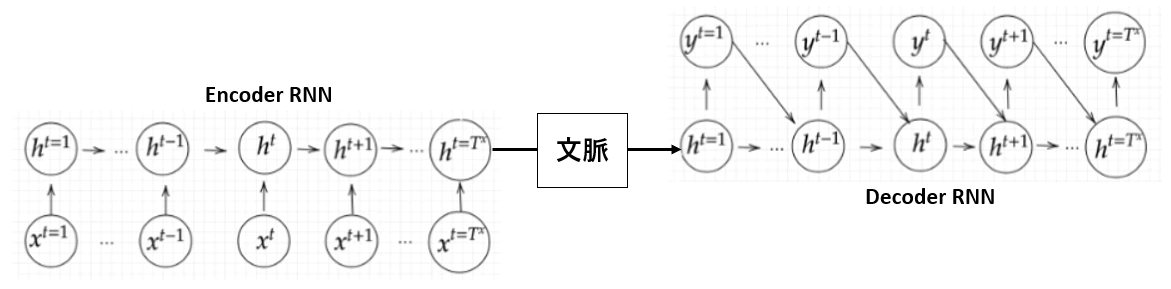
Encoder RNN ・テキストデータを単語等のトークンに区切る ・単語をone-hotベクトルにしてベクトル表現を得る(数万から数十万) - ほとんどがゼロのため、もったいない ・embeddingでのベクトルの大きさは数百程度に抑え込む(機械学習を用いる) - 単語が似通った場合には、似通ったベクトル表現になるように学習する(ただし、難しい) - embedding表現を入力値としてとる ・final stateがそれまでの入力を記憶した、文脈ベクトル ・Masked Language Model(推論モデル) - 似たような意味の単語が似通ったベクトル表現に自然と落ち着いていく - 一文中の単語をランダムに落とすなどすれば、教師データとしてラベリングする必要もなく、大量にデータが得られる - Googleが作ったBERTが有名
Decoder RNN
・システムがアウトプットデータを単語等のトークンごとに生成する構造
例:
お腹 が 痛い です 。
・一番最初に入ってくるのはEncoderからの出力(文の意味)で、一単語目を作成、その後は次々に次の単語を予測していく
・ベクトル表現から、どれが一番近い単語かを予測していく
確認テスト

答え
(2)
演習チャレンジ
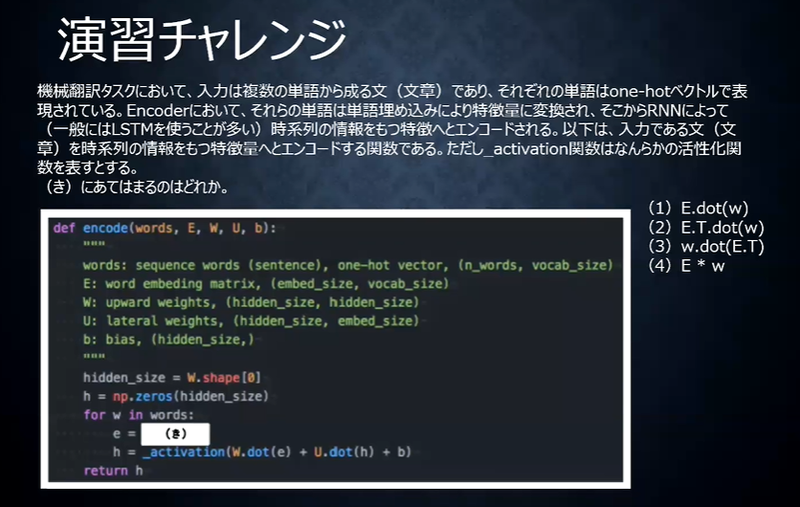
答え
(1)
HRED
・Seq2seqの課題は一問一答しかできない(文脈もなく、応答するのみ) ・文の意味ベクトルをつないでいく(RNNの多重構造) ・過去のn-1個の発話から次の発話を生成する ・前の単語の流れに即して応答されるため、より人間らしい文章になる ・Seq2seq + Context RNN(Encoderのまとめた各文章の系列をまとめて、これまでの会話コンテキスト全体を表すベクトルに変換する構造) ⇒ 過去の発話の履歴を加味した返答が可能 ・課題は以下 - 多様性がない(短く情報量に乏しい答えをしがちである) - 短く、よくある答えを学ぶ傾向がある(「うん」、「そうだね」)
VHRED
・HREDにVAEの潜在変数の概念を追加したもの - それにより、HREDの課題を解決
確認テスト

答え
seq2seq :
一問一答しか対応できない
HRED :
過去の文章の意味ベクトルを記憶して、文脈に沿った対応ができるが、
多様性がない解答になりがち
VHRED :
VAEの概念を導入して、回答に多様性を持たせることができる
オートエンコーダ
・教師無し学習の一つ - 訓練データのみで教師データは不要 ・次元削減が可能 ・入力と出力が同じになるように学習する
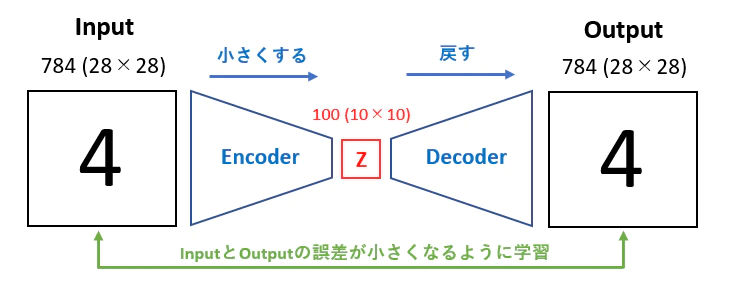
VAE(Valuational Auto Encoder) - 中間層の潜在変数zに確率分布を仮定したもの - 元のデータが近ければ、同じようなベクトル表現になってほしいが、何も指定しないと、全く異なるベクトル表現になる可能性がある(デコーダーの入力にランダム性を持たせる(ノイズを加える)) > ノイズ付きのデータに対しても同じ出力を出すように学習するので、汎用的な出力になる
確認テスト

答え
確率変数
Section6:Word2vec
Word2Vec
単語をベクトル表現にする手法(embedding表現を得る手法) 変換するときの変換表を学習する
推論ベースの手法 シンプルな2層のニューラルネットワークで構成されている
学習データからボキャブラリーを作成し、各単語をone-hotベクトルにして入力し単語分散表現を得ることができる。
skip-gramモデルとCBOWモデルがある CBOWモデルは複数の単語(コンテキスト)から一つの単語(ターゲット)を推測 skip-gramモデルは一つの単語から複数の単語を推測
word2Vecは重みの再学習ができるため、単語の分散表現の更新や追加が効率的に行える。
Section7:Attention Mechanism
Seq2Seqは文章の単語数に関わらず、常に固定次元ベクトルで入力しなければならないため、長い文章への対応が難しい 文章が長くなるほどそのシーケンスの内部表現の次元も大きくなっていく仕組みが必要となる
Attention Mechanismとは、「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組みのこと。
ソフトマックス関数等で確率分布を得て、重み付き平均を得る手法をSoft Attentionという。 Soft Attentionのように重み付け平均せず、重みが最大となるValueを取り出したり、重み行列を確率分布とみなして抽出する手法をHard Attentionという。
・入力と出力のどの単語が関連しているのかの関連度を学習する仕組み - 文章が長くなっても重要な情報のみをピックアップできる - 近年のモデルはほとんどこれを用いている
確認テスト

答え
RNN : 時系列データの処理に用いる word2vec : 単語をベクトルに表現する手法 seq2seq : 2つの時系列データをドッキングしたもの Attention : 入力と出力のどの単語が関連しているのかの関連度を学習する仕組み
実装演習
activation_functions.ipynb